
"Programming with libxml2 is like the thrilling embrace of an exotic stranger." Mark Pilgrim
Libxml2 is the XML C parser and toolkit developed for the Gnome project (but usable outside of the Gnome platform), it is free software available under the MIT License. XML itself is a metalanguage to design markup languages, i.e. text language where semantic and structure are added to the content using extra "markup" information enclosed between angle brackets. HTML is the most well-known markup language. Though the library is written in C a variety of language bindings make it available in other environments.
Libxml2 is known to be very portable, the library should build and work without serious troubles on a variety of systems (Linux, Unix, Windows, CygWin, MacOS, MacOS X, RISC Os, OS/2, VMS, QNX, MVS, ...)
Libxml2 implements a number of existing standards related to markup languages:
In most cases libxml2 tries to implement the specifications in a relatively strictly compliant way. As of release 2.4.16, libxml2 passed all 1800+ tests from the OASIS XML Tests Suite.
To some extent libxml2 provides support for the following additional specifications but doesn't claim to implement them completely:
A partial implementation of XML Schemas Part 1: Structure is being worked on but it would be far too early to make any conformance statement about it at the moment.
Separate documents:
Logo designed by Marc Liyanage.
This document describes libxml, the XML C parser and toolkit developed for the Gnome project. XML is a standard for building tag-based structured documents/data.
Here are some key points about libxml:
Warning: unless you are forced to because your application links with a Gnome-1.X library requiring it, Do Not Use libxml1, use libxml2
Table of Contents:
libxml2 is released under the MIT License; see the file Copyright in the distribution for the precise wording
Yes. The MIT License allows you to keep proprietary the changes you made to libxml, but it would be graceful to send-back bug fixes and improvements as patches for possible incorporation in the main development tree.
The original distribution comes from rpmfind.net or gnome.org
Most Linux and BSD distributions include libxml, this is probably the safer way for end-users to use libxml.
David Doolin provides precompiled Windows versions at http://www.ce.berkeley.edu/~doolin/code/libxmlwin32/
You probably have an old libxml0 package used to provide the shared library for libxml.so.0, you can probably safely remove it. The libxml packages provided on rpmfind.net provide libxml.so.0
The most generic solution is to re-fetch the latest src.rpm , and rebuild it locally with
rpm --rebuild libxml(2)-xxx.src.rpm.
If everything goes well it will generate two binary rpm packages (one providing the shared libs and xmllint, and the other one, the -devel package, providing includes, static libraries and scripts needed to build applications with libxml(2)) that you can install locally.
As most UNIX libraries libxml2 follows the "standard":
gunzip -c xxx.tar.gz | tar xvf -
cd libxml-xxxx
./configure --help
to see the options, then the compilation/installation proper
./configure [possible options]
make
make install
At that point you may have to rerun ldconfig or a similar utility to update your list of installed shared libs.
Libxml2 does not require any other library, the normal C ANSI API should be sufficient (please report any violation to this rule you may find).
However if found at configuration time libxml2 will detect and use the following libs:
Sometimes the regression tests' results don't completely match the value produced by the parser, and the makefile uses diff to print the delta. On some platforms the diff return breaks the compilation process; if the diff is small this is probably not a serious problem.
Sometimes (especially on Solaris) make checks fail due to limitations in make. Try using GNU-make instead.
The configure script (and other Makefiles) are generated. Use the autogen.sh script to regenerate the configure script and Makefiles, like:
./autogen.sh --prefix=/usr --disable-shared
It seems the initial release of gcc-3.0 has a problem with the optimizer which miscompiles the URI module. Please use another compiler.
Usually the problem comes from the fact that the compiler doesn't get
the right compilation or linking flags. There is a small shell script
xml2-config which is installed as part of libxml2 usual
install process which provides those flags. Use
xml2-config --cflags
to get the compilation flags and
xml2-config --libs
to get the linker flags. Usually this is done directly from the Makefile as:
CFLAGS=`xml2-config --cflags`
LIBS=`xml2-config --libs`
Libxml2 will not invent spaces in the content of a document since all spaces in the content of a document are significant. If you build a tree from the API and want indentation:
For a XML file as below:
<?xml version="1.0"?> <PLAN xmlns="http://www.argus.ca/autotest/1.0/"> <NODE CommFlag="0"/> <NODE CommFlag="1"/> </PLAN>
after parsing it with the function pxmlDoc=xmlParseFile(...);
I want to the get the content of the first node (node with the CommFlag="0")
so I did it as following;
xmlNodePtr pnode; pnode=pxmlDoc->children->children;
but it does not work. If I change it to
pnode=pxmlDoc->children->children->next;
then it works. Can someone explain it to me.
In XML all characters in the content of the document are significant including blanks and formatting line breaks.
The extra nodes you are wondering about are just that, text nodes with the formatting spaces which are part of the document but that people tend to forget. There is a function xmlKeepBlanksDefault () to remove those at parse time, but that's an heuristic, and its use should be limited to cases where you are certain there is no mixed-content in the document.
You are compiling code developed for libxml version 1 and using a libxml2 development environment. Either switch back to libxml v1 devel or even better fix the code to compile with libxml2 (or both) by following the instructions.
The source code you are using has been upgraded to be able to compile with both libxml and libxml2, but you need to install a more recent version: libxml(-devel) >= 1.8.8 or libxml2(-devel) >= 2.1.0
XPath implementation prior to 2.3.0 was really incomplete. Upgrade to a recent version, there are no known bugs in the current version.
It's hard to maintain the documentation in sync with the code <grin/> ...
Check the previous points 1/ and 2/ raised before, and please send patches.
Ideally a libxml2 book would be nice. I have no such plan ... But you can:
http://cvs.gnome.org/lxr/search?string=xmlAddChild
This may be slow, a large hardware donation to the gnome project could cure this :-)
libxml2 is written in pure C in order to allow easy reuse on a number of platforms, including embedded systems. I don't intend to convert to C++.
There is however a C++ wrapper which may fulfill your needs:
Website: http://libxmlplusplus.sourceforge.net/
Download: http://sourceforge.net/project/showfiles.php?group_id=12999
It is possible to validate documents which had not been validated at initial parsing time or documents which have been built from scratch using the API. Use the xmlValidateDtd() function. It is also possible to simply add a DTD to an existing document:
xmlDocPtr doc; /* your existing document */
xmlDtdPtr dtd = xmlParseDTD(NULL, filename_of_dtd); /* parse the DTD */
dtd->name = xmlStrDup((xmlChar*)"root_name"); /* use the given root */
doc->intSubset = dtd;
if (doc->children == NULL) xmlAddChild((xmlNodePtr)doc, (xmlNodePtr)dtd);
else xmlAddPrevSibling(doc->children, (xmlNodePtr)dtd);
It is a null terminated sequence of utf-8 characters. And only utf-8! You need to convert strings encoded in different ways to utf-8 before passing them to the API. This can be accomplished with the iconv library for instance.
There are several on-line resources related to using libxml:
Well, bugs or missing features are always possible, and I will make a point of fixing them in a timely fashion. The best way to report a bug is to use the Gnome bug tracking database (make sure to use the "libxml2" module name). I look at reports there regularly and it's good to have a reminder when a bug is still open. Be sure to specify that the bug is for the package libxml2.
For small problems you can try to get help on IRC, the #xml channel on irc.gnome.org (port 6667) usually have a few person subscribed which may help (but there is no garantee and if a real issue is raised it should go on the mailing-list for archival).
There is also a mailing-list xml@gnome.org for libxml, with an on-line archive (old). To subscribe to this list, please visit the associated Web page and follow the instructions. Do not send code, I won't debug it (but patches are really appreciated!).
Please note that with the current amount of virus and SPAM, sending mail to the list without being subscribed won't work. There is *far too many bounces* (in the order of a thousand a day !) I cannot approve them manually anymore. If your mail to the list bounced waiting for administrator approval, it is LOST ! Repost it and fix the problem triggering the error.
Check the following before posting:
Then send the bug with associated information to reproduce it to the xml@gnome.org list; if it's really libxml related I will approve it. Please do not send mail to me directly, it makes things really hard to track and in some cases I am not the best person to answer a given question, ask on the list.
To be really clear about support:
Of course, bugs reported with a suggested patch for fixing them will probably be processed faster than those without.
If you're looking for help, a quick look at the list archive may actually provide the answer. I usually send source samples when answering libxml2 usage questions. The auto-generated documentation is not as polished as I would like (i need to learn more about DocBook), but it's a good starting point.
You can help the project in various ways, the best thing to do first is to subscribe to the mailing-list as explained before, check the archives and the Gnome bug database:
The latest versions of libxml2 can be found on the xmlsoft.org server ( HTTP, FTP and rsync are available), there is also mirrors (Australia( Web), France) or on the Gnome FTP server as source archive , Antonin Sprinzl also provide a mirror in Austria. (NOTE that you need both the libxml(2) and libxml(2)-devel packages installed to compile applications using libxml.)
You can find all the history of libxml(2) and libxslt releases in the old directory. The precompiled Windows binaries made by Igor Zlatovic are available in the win32 directory.
Binary ports:
If you know other supported binary ports, please contact me.
I do accept external contributions, especially if compiling on another platform, get in touch with the list to upload the package, wrappers for various languages have been provided, and can be found in the bindings section
Libxml2 is also available from CVS:
The Gnome CVS base. Check the Gnome CVS Tools page; the CVS module is libxml2.
Items not finished and worked on, get in touch with the list if you want to help those
The change log describes the recents commits to the CVS code base.
There is the list of public releases:
A bugfix only release:
A bugfixes only release
2 serialization bugs, node info generation problems, a DTD regexp generation problem.
2.4.24: Aug 22 2002
This release is both a bug fix release and also contains the early XML Schemas structures and datatypes code, beware, all interfaces are likely to change, there is huge holes, it is clearly a work in progress and don't even think of putting this code in a production system, it's actually not compiled in by default. The real fixes are:
Lots of bugfixes, and added a basic SGML catalog support:
#include <libxml/xxx.h>
instead of
#include "xxx.h"
XML is a standard for markup-based structured documents. Here is an example XML document:
<?xml version="1.0"?> <EXAMPLE prop1="gnome is great" prop2="& linux too"> <head> <title>Welcome to Gnome</title> </head> <chapter> <title>The Linux adventure</title> <p>bla bla bla ...</p> <image href="linus.gif"/> <p>...</p> </chapter> </EXAMPLE>
The first line specifies that it is an XML document and gives useful
information about its encoding. Then the rest of the document is a text
format whose structure is specified by tags between brackets. Each
tag opened has to be closed. XML is pedantic about this. However, if
a tag is empty (no content), a single tag can serve as both the opening and
closing tag if it ends with /> rather than with
>. Note that, for example, the image tag has no content (just
an attribute) and is closed by ending the tag with />.
XML can be applied successfully to a wide range of tasks, ranging from long term structured document maintenance (where it follows the steps of SGML) to simple data encoding mechanisms like configuration file formatting (glade), spreadsheets (gnumeric), or even shorter lived documents such as WebDAV where it is used to encode remote calls between a client and a server.
Check the separate libxslt page
XSL Transformations, is a language for transforming XML documents into other XML documents (or HTML/textual output).
A separate library called libxslt is available implementing XSLT-1.0 for libxml2. This module "libxslt" too can be found in the Gnome CVS base.
You can check the features supported and the progresses on the Changelog.
There are a number of language bindings and wrappers available for libxml2, the list below is not exhaustive. Please contact the xml-bindings@gnome.org (archives) in order to get updates to this list or to discuss the specific topic of libxml2 or libxslt wrappers or bindings:
The distribution includes a set of Python bindings, which are guaranteed to be maintained as part of the library in the future, though the Python interface have not yet reached the completeness of the C API.
St�phane Bidoul maintains a Windows port of the Python bindings.
Note to people interested in building bindings, the API is formalized as an XML API description file which allows to automate a large part of the Python bindings, this includes function descriptions, enums, structures, typedefs, etc... The Python script used to build the bindings is python/generator.py in the source distribution.
To install the Python bindings there are 2 options:
The distribution includes a set of examples and regression tests for the
python bindings in the python/tests directory. Here are some
excerpts from those tests:
This is a basic test of the file interface and DOM navigation:
import libxml2, sys
doc = libxml2.parseFile("tst.xml")
if doc.name != "tst.xml":
print "doc.name failed"
sys.exit(1)
root = doc.children
if root.name != "doc":
print "root.name failed"
sys.exit(1)
child = root.children
if child.name != "foo":
print "child.name failed"
sys.exit(1)
doc.freeDoc()
The Python module is called libxml2; parseFile is the equivalent of xmlParseFile (most of the bindings are automatically generated, and the xml prefix is removed and the casing convention are kept). All node seen at the binding level share the same subset of accessors:
name : returns the node nametype : returns a string indicating the node typecontent : returns the content of the node, it is based on
xmlNodeGetContent() and hence is recursive.parent , children, last,
next, prev, doc,
properties: pointing to the associated element in the tree,
those may return None in case no such link exists.Also note the need to explicitly deallocate documents with freeDoc() . Reference counting for libxml2 trees would need quite a lot of work to function properly, and rather than risk memory leaks if not implemented correctly it sounds safer to have an explicit function to free a tree. The wrapper python objects like doc, root or child are them automatically garbage collected.
This test check the validation interfaces and redirection of error messages:
import libxml2
#deactivate error messages from the validation
def noerr(ctx, str):
pass
libxml2.registerErrorHandler(noerr, None)
ctxt = libxml2.createFileParserCtxt("invalid.xml")
ctxt.validate(1)
ctxt.parseDocument()
doc = ctxt.doc()
valid = ctxt.isValid()
doc.freeDoc()
if valid != 0:
print "validity check failed"
The first thing to notice is the call to registerErrorHandler(), it defines a new error handler global to the library. It is used to avoid seeing the error messages when trying to validate the invalid document.
The main interest of that test is the creation of a parser context with createFileParserCtxt() and how the behaviour can be changed before calling parseDocument() . Similarly the informations resulting from the parsing phase are also available using context methods.
Contexts like nodes are defined as class and the libxml2 wrappers maps the C function interfaces in terms of objects method as much as possible. The best to get a complete view of what methods are supported is to look at the libxml2.py module containing all the wrappers.
This test show how to activate the push parser interface:
import libxml2
ctxt = libxml2.createPushParser(None, "<foo", 4, "test.xml")
ctxt.parseChunk("/>", 2, 1)
doc = ctxt.doc()
doc.freeDoc()
The context is created with a special call based on the xmlCreatePushParser() from the C library. The first argument is an optional SAX callback object, then the initial set of data, the length and the name of the resource in case URI-References need to be computed by the parser.
Then the data are pushed using the parseChunk() method, the last call setting the third argument terminate to 1.
this test show the use of the event based parsing interfaces. In this case the parser does not build a document, but provides callback information as the parser makes progresses analyzing the data being provided:
import libxml2
log = ""
class callback:
def startDocument(self):
global log
log = log + "startDocument:"
def endDocument(self):
global log
log = log + "endDocument:"
def startElement(self, tag, attrs):
global log
log = log + "startElement %s %s:" % (tag, attrs)
def endElement(self, tag):
global log
log = log + "endElement %s:" % (tag)
def characters(self, data):
global log
log = log + "characters: %s:" % (data)
def warning(self, msg):
global log
log = log + "warning: %s:" % (msg)
def error(self, msg):
global log
log = log + "error: %s:" % (msg)
def fatalError(self, msg):
global log
log = log + "fatalError: %s:" % (msg)
handler = callback()
ctxt = libxml2.createPushParser(handler, "<foo", 4, "test.xml")
chunk = " url='tst'>b"
ctxt.parseChunk(chunk, len(chunk), 0)
chunk = "ar</foo>"
ctxt.parseChunk(chunk, len(chunk), 1)
reference = "startDocument:startElement foo {'url': 'tst'}:" + \
"characters: bar:endElement foo:endDocument:"
if log != reference:
print "Error got: %s" % log
print "Expected: %s" % reference
The key object in that test is the handler, it provides a number of entry points which can be called by the parser as it makes progresses to indicate the information set obtained. The full set of callback is larger than what the callback class in that specific example implements (see the SAX definition for a complete list). The wrapper will only call those supplied by the object when activated. The startElement receives the names of the element and a dictionary containing the attributes carried by this element.
Also note that the reference string generated from the callback shows a single character call even though the string "bar" is passed to the parser from 2 different call to parseChunk()
This is a basic test of XPath wrappers support
import libxml2
doc = libxml2.parseFile("tst.xml")
ctxt = doc.xpathNewContext()
res = ctxt.xpathEval("//*")
if len(res) != 2:
print "xpath query: wrong node set size"
sys.exit(1)
if res[0].name != "doc" or res[1].name != "foo":
print "xpath query: wrong node set value"
sys.exit(1)
doc.freeDoc()
ctxt.xpathFreeContext()
This test parses a file, then create an XPath context to evaluate XPath expression on it. The xpathEval() method execute an XPath query and returns the result mapped in a Python way. String and numbers are natively converted, and node sets are returned as a tuple of libxml2 Python nodes wrappers. Like the document, the XPath context need to be freed explicitly, also not that the result of the XPath query may point back to the document tree and hence the document must be freed after the result of the query is used.
This test shows how to extend the XPath engine with functions written in python:
import libxml2
def foo(ctx, x):
return x + 1
doc = libxml2.parseFile("tst.xml")
ctxt = doc.xpathNewContext()
libxml2.registerXPathFunction(ctxt._o, "foo", None, foo)
res = ctxt.xpathEval("foo(1)")
if res != 2:
print "xpath extension failure"
doc.freeDoc()
ctxt.xpathFreeContext()
Note how the extension function is registered with the context (but that part is not yet finalized, this may change slightly in the future).
This test is similar to the previous one but shows how the extension function can access the XPath evaluation context:
def foo(ctx, x):
global called
#
# test that access to the XPath evaluation contexts
#
pctxt = libxml2.xpathParserContext(_obj=ctx)
ctxt = pctxt.context()
called = ctxt.function()
return x + 1
All the interfaces around the XPath parser(or rather evaluation) context are not finalized, but it should be sufficient to do contextual work at the evaluation point.
last but not least, all tests starts with the following prologue:
#memory debug specific libxml2.debugMemory(1)
and ends with the following epilogue:
#memory debug specific
libxml2.cleanupParser()
if libxml2.debugMemory(1) == 0:
print "OK"
else:
print "Memory leak %d bytes" % (libxml2.debugMemory(1))
libxml2.dumpMemory()
Those activate the memory debugging interface of libxml2 where all
allocated block in the library are tracked. The prologue then cleans up the
library state and checks that all allocated memory has been freed. If not it
calls dumpMemory() which saves that list in a .memdump file.
Libxml2 is made of multiple components; some of them are optional, and most of the block interfaces are public. The main components are:
Graphically this gives the following:
The parser returns a tree built during the document analysis. The value returned is an xmlDocPtr (i.e., a pointer to an xmlDoc structure). This structure contains information such as the file name, the document type, and a children pointer which is the root of the document (or more exactly the first child under the root which is the document). The tree is made of xmlNodes, chained in double-linked lists of siblings and with a children<->parent relationship. An xmlNode can also carry properties (a chain of xmlAttr structures). An attribute may have a value which is a list of TEXT or ENTITY_REF nodes.
Here is an example (erroneous with respect to the XML spec since there should be only one ELEMENT under the root):
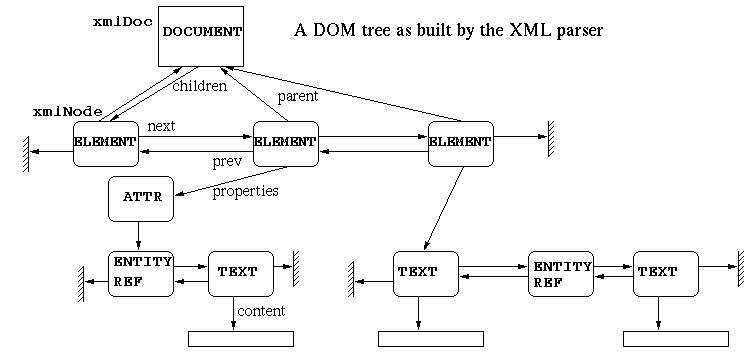
In the source package there is a small program (not installed by default) called xmllint which parses XML files given as argument and prints them back as parsed. This is useful for detecting errors both in XML code and in the XML parser itself. It has an option --debug which prints the actual in-memory structure of the document; here is the result with the example given before:
DOCUMENT
version=1.0
standalone=true
ELEMENT EXAMPLE
ATTRIBUTE prop1
TEXT
content=gnome is great
ATTRIBUTE prop2
ENTITY_REF
TEXT
content= linux too
ELEMENT head
ELEMENT title
TEXT
content=Welcome to Gnome
ELEMENT chapter
ELEMENT title
TEXT
content=The Linux adventure
ELEMENT p
TEXT
content=bla bla bla ...
ELEMENT image
ATTRIBUTE href
TEXT
content=linus.gif
ELEMENT p
TEXT
content=...
This should be useful for learning the internal representation model.
Sometimes the DOM tree output is just too large to fit reasonably into memory. In that case (and if you don't expect to save back the XML document loaded using libxml), it's better to use the SAX interface of libxml. SAX is a callback-based interface to the parser. Before parsing, the application layer registers a customized set of callbacks which are called by the library as it progresses through the XML input.
To get more detailed step-by-step guidance on using the SAX interface of libxml, see the nice documentation.written by James Henstridge.
You can debug the SAX behaviour by using the testSAX program located in the gnome-xml module (it's usually not shipped in the binary packages of libxml, but you can find it in the tar source distribution). Here is the sequence of callbacks that would be reported by testSAX when parsing the example XML document shown earlier:
SAX.setDocumentLocator() SAX.startDocument() SAX.getEntity(amp) SAX.startElement(EXAMPLE, prop1='gnome is great', prop2='& linux too') SAX.characters( , 3) SAX.startElement(head) SAX.characters( , 4) SAX.startElement(title) SAX.characters(Welcome to Gnome, 16) SAX.endElement(title) SAX.characters( , 3) SAX.endElement(head) SAX.characters( , 3) SAX.startElement(chapter) SAX.characters( , 4) SAX.startElement(title) SAX.characters(The Linux adventure, 19) SAX.endElement(title) SAX.characters( , 4) SAX.startElement(p) SAX.characters(bla bla bla ..., 15) SAX.endElement(p) SAX.characters( , 4) SAX.startElement(image, href='linus.gif') SAX.endElement(image) SAX.characters( , 4) SAX.startElement(p) SAX.characters(..., 3) SAX.endElement(p) SAX.characters( , 3) SAX.endElement(chapter) SAX.characters( , 1) SAX.endElement(EXAMPLE) SAX.endDocument()
Most of the other interfaces of libxml2 are based on the DOM tree-building facility, so nearly everything up to the end of this document presupposes the use of the standard DOM tree build. Note that the DOM tree itself is built by a set of registered default callbacks, without internal specific interface.
Table of Content:
Well what is validation and what is a DTD ?
DTD is the acronym for Document Type Definition. This is a description of the content for a family of XML files. This is part of the XML 1.0 specification, and allows one to describe and verify that a given document instance conforms to the set of rules detailing its structure and content.
Validation is the process of checking a document against a DTD (more generally against a set of construction rules).
The validation process and building DTDs are the two most difficult parts of the XML life cycle. Briefly a DTD defines all the possible elements to be found within your document, what is the formal shape of your document tree (by defining the allowed content of an element; either text, a regular expression for the allowed list of children, or mixed content i.e. both text and children). The DTD also defines the valid attributes for all elements and the types of those attributes.
The W3C XML Recommendation (Tim Bray's annotated version of Rev1):
(unfortunately) all this is inherited from the SGML world, the syntax is ancient...
Writing DTDs can be done in many ways. The rules to build them if you need something permanent or something which can evolve over time can be radically different. Really complex DTDs like DocBook ones are flexible but quite harder to design. I will just focus on DTDs for a formats with a fixed simple structure. It is just a set of basic rules, and definitely not exhaustive nor usable for complex DTD design.
Assuming the top element of the document is spec and the dtd
is placed in the file mydtd in the subdirectory
dtds of the directory from where the document were loaded:
<!DOCTYPE spec SYSTEM "dtds/mydtd">
Notes:
PUBLIC identifier (a
magic string) so that the DTD is looked up in catalogs on the client side
without having to locate it on the web.DOCTYPE declaration.The following declares an element spec:
<!ELEMENT spec (front, body, back?)>
It also expresses that the spec element contains one front,
one body and one optional back children elements in
this order. The declaration of one element of the structure and its content
are done in a single declaration. Similarly the following declares
div1 elements:
<!ELEMENT div1 (head, (p | list | note)*, div2?)>
which means div1 contains one head then a series of optional
p, lists and notes and then an
optional div2. And last but not least an element can contain
text:
<!ELEMENT b (#PCDATA)>
b contains text or being of mixed content (text and elements
in no particular order):
<!ELEMENT p (#PCDATA|a|ul|b|i|em)*>
p can contain text or a, ul,
b, i or em elements in no particular
order.
Again the attributes declaration includes their content definition:
<!ATTLIST termdef name CDATA #IMPLIED>
means that the element termdef can have a name
attribute containing text (CDATA) and which is optional
(#IMPLIED). The attribute value can also be defined within a
set:
<!ATTLIST list type (bullets|ordered|glossary)
"ordered">
means list element have a type attribute with 3
allowed values "bullets", "ordered" or "glossary" and which default to
"ordered" if the attribute is not explicitly specified.
The content type of an attribute can be text (CDATA),
anchor/reference/references
(ID/IDREF/IDREFS), entity(ies)
(ENTITY/ENTITIES) or name(s)
(NMTOKEN/NMTOKENS). The following defines that a
chapter element can have an optional id attribute
of type ID, usable for reference from attribute of type
IDREF:
<!ATTLIST chapter id ID #IMPLIED>
The last value of an attribute definition can be #REQUIRED
meaning that the attribute has to be given, #IMPLIED
meaning that it is optional, or the default value (possibly prefixed by
#FIXED if it is the only allowed).
Notes:
<!ATTLIST termdef
id ID #REQUIRED
name CDATA #IMPLIED>
The previous construct defines both id and
name attributes for the element termdef.
The directory test/valid/dtds/ in the libxml2 distribution
contains some complex DTD examples. The example in the file
test/valid/dia.xml shows an XML file where the simple DTD is
directly included within the document.
The simplest way is to use the xmllint program included with libxml. The
--valid option turns-on validation of the files given as input.
For example the following validates a copy of the first revision of the XML
1.0 specification:
xmllint --valid --noout test/valid/REC-xml-19980210.xml
the -- noout is used to disable output of the resulting tree.
The --dtdvalid dtd allows validation of the document(s)
against a given DTD.
Libxml2 exports an API to handle DTDs and validation, check the associated description.
DTDs are as old as SGML. So there may be a number of examples on-line, I will just list one for now, others pointers welcome:
I suggest looking at the examples found under test/valid/dtd and any of the large number of books available on XML. The dia example in test/valid should be both simple and complete enough to allow you to build your own.
Table of Content:
The module xmlmemory.h
provides the interfaces to the libxml2 memory system:
It is sometimes useful to not use the default memory allocator, either for debugging, analysis or to implement a specific behaviour on memory management (like on embedded systems). Two function calls are available to do so:
Of course a call to xmlMemSetup() should probably be done before calling any other libxml2 routines (unless you are sure your allocations routines are compatibles).
Libxml2 is not stateless, there is a few set of memory structures needing allocation before the parser is fully functional (some encoding structures for example). This also mean that once parsing is finished there is a tiny amount of memory (a few hundred bytes) which can be recollected if you don't reuse the parser immediately:
Generally xmlCleanupParser() is safe, if needed the state will be rebuild at the next invocation of parser routines, but be careful of the consequences in multithreaded applications.
When configured using --with-mem-debug flag (off by default), libxml2 uses a set of memory allocation debugging routines keeping track of all allocated blocks and the location in the code where the routine was called. A couple of other debugging routines allow to dump the memory allocated infos to a file or call a specific routine when a given block number is allocated:
.memdump fileWhen developing libxml2 memory debug is enabled, the tests programs call xmlMemoryDump () and the "make test" regression tests will check for any memory leak during the full regression test sequence, this helps a lot ensuring that libxml2 does not leak memory and bullet proof memory allocations use (some libc implementations are known to be far too permissive resulting in major portability problems!).
If the .memdump reports a leak, it displays the allocation function and also tries to give some informations about the content and structure of the allocated blocks left. This is sufficient in most cases to find the culprit, but not always. Assuming the allocation problem is reproducible, it is possible to find more easily:
set environment XML_MEM_BREAKPOINT xxxx
before running the program.
I used to use a commercial tool to debug libxml2 memory problems but after noticing that it was not detecting memory leaks that simple mechanism was used and proved extremely efficient until now. Lately I have also used valgrind with quite some success, it is tied to the i386 architecture since it works by emulating the processor and instruction set, it is slow but extremely efficient, i.e. it spot memory usage errors in a very precise way.
How much libxml2 memory require ? It's hard to tell in average it depends of a number of things:
Table of Content:
If you are not really familiar with Internationalization (usual shortcut is I18N) , Unicode, characters and glyphs, I suggest you read a presentation by Tim Bray on Unicode and why you should care about it.
XML was designed from the start to allow the support of any character set by using Unicode. Any conformant XML parser has to support the UTF-8 and UTF-16 default encodings which can both express the full unicode ranges. UTF8 is a variable length encoding whose greatest points are to reuse the same encoding for ASCII and to save space for Western encodings, but it is a bit more complex to handle in practice. UTF-16 use 2 bytes per character (and sometimes combines two pairs), it makes implementation easier, but looks a bit overkill for Western languages encoding. Moreover the XML specification allows the document to be encoded in other encodings at the condition that they are clearly labeled as such. For example the following is a wellformed XML document encoded in ISO-8859-1 and using accentuated letters that we French like for both markup and content:
<?xml version="1.0" encoding="ISO-8859-1"?> <tr�s>l�</tr�s>
Having internationalization support in libxml2 means the following:
Another very important point is that the whole libxml2 API, with the exception of a few routines to read with a specific encoding or save to a specific encoding, is completely agnostic about the original encoding of the document.
It should be noted too that the HTML parser embedded in libxml2 now obey the same rules too, the following document will be (as of 2.2.2) handled in an internationalized fashion by libxml2 too:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN"
"http://www.w3.org/TR/REC-html40/loose.dtd">
<html lang="fr">
<head>
<META HTTP-EQUIV="Content-Type" CONTENT="text/html; charset=ISO-8859-1">
</head>
<body>
<p>W3C cr�e des standards pour le Web.</body>
</html>
One of the core decisions was to force all documents to be converted to a default internal encoding, and that encoding to be UTF-8, here are the rationales for those choices:
What does this mean in practice for the libxml2 user:
Let's describe how all this works within libxml, basically the I18N (internationalization) support get triggered only during I/O operation, i.e. when reading a document or saving one. Let's look first at the reading sequence:
~/XML -> ./xmllint err.xml err.xml:1: error: Input is not proper UTF-8, indicate encoding ! <tr�s>l�</tr�s> ^ err.xml:1: error: Bytes: 0xE8 0x73 0x3E 0x6C <tr�s>l�</tr�s> ^
~/XML -> ./xmllint err2.xml
err2.xml:1: error: Unsupported encoding UnsupportedEnc
<?xml version="1.0" encoding="UnsupportedEnc"?>
^
Ok then what happens when saving the document (assuming you collected/built an xmlDoc DOM like structure) ? It depends on the function called, xmlSaveFile() will just try to save in the original encoding, while xmlSaveFileTo() and xmlSaveFileEnc() can optionally save to a given encoding:
otherwise everything is written in the internal form, i.e. UTF-8
Here are a few examples based on the same test document:
~/XML -> ./xmllint isolat1 <?xml version="1.0" encoding="ISO-8859-1"?> <tr�s>l�</tr�s> ~/XML -> ./xmllint --encode UTF-8 isolat1 <?xml version="1.0" encoding="UTF-8"?> <très>l� �</très> ~/XML ->
The same processing is applied (and reuse most of the code) for HTML I18N processing. Looking up and modifying the content encoding is a bit more difficult since it is located in a <meta> tag under the <head>, so a couple of functions htmlGetMetaEncoding() and htmlSetMetaEncoding() have been provided. The parser also attempts to switch encoding on the fly when detecting such a tag on input. Except for that the processing is the same (and again reuses the same code).
libxml2 has a set of default converters for the following encodings (located in encoding.c):
More over when compiled on an Unix platform with iconv support the full set of encodings supported by iconv can be instantly be used by libxml. On a linux machine with glibc-2.1 the list of supported encodings and aliases fill 3 full pages, and include UCS-4, the full set of ISO-Latin encodings, and the various Japanese ones.
From 2.2.3, libxml2 has support to register encoding names aliases. The goal is to be able to parse document whose encoding is supported but where the name differs (for example from the default set of names accepted by iconv). The following functions allow to register and handle new aliases for existing encodings. Once registered libxml2 will automatically lookup the aliases when handling a document:
Well adding support for new encoding, or overriding one of the encoders (assuming it is buggy) should not be hard, just write input and output conversion routines to/from UTF-8, and register them using xmlNewCharEncodingHandler(name, xxxToUTF8, UTF8Toxxx), and they will be called automatically if the parser(s) encounter such an encoding name (register it uppercase, this will help). The description of the encoders, their arguments and expected return values are described in the encoding.h header.
A quick note on the topic of subverting the parser to use a different internal encoding than UTF-8, in some case people will absolutely want to keep the internal encoding different, I think it's still possible (but the encoding must be compliant with ASCII on the same subrange) though I didn't tried it. The key is to override the default conversion routines (by registering null encoders/decoders for your charsets), and bypass the UTF-8 checking of the parser by setting the parser context charset (ctxt->charset) to something different than XML_CHAR_ENCODING_UTF8, but there is no guarantee that this will work. You may also have some troubles saving back.
Basically proper I18N support is important, this requires at least libxml-2.0.0, but a lot of features and corrections are really available only starting 2.2.
Table of Content:
The module xmlIO.h provides
the interfaces to the libxml2 I/O system. This consists of 4 main parts:
xmlGetExternalEntityLoader() and
xmlSetExternalEntityLoader(). Check the
example.This affect the default I/O operations and allows to use specific I/O handlers for certain names.
The general mechanism used when loading http://rpmfind.net/xml.html for example in the HTML parser is the following:
xmlNewInputFromFile() with
the parsing context and the URI string.The user defined callbacks are checked first to allow overriding of the default libxml2 I/O routines.
All the buffer manipulation handling is done using the
xmlBuffer type define in tree.h which is a
resizable memory buffer. The buffer allocation strategy can be selected to be
either best-fit or use an exponential doubling one (CPU vs. memory use
trade-off). The values are XML_BUFFER_ALLOC_EXACT and
XML_BUFFER_ALLOC_DOUBLEIT, and can be set individually or on a
system wide basis using xmlBufferSetAllocationScheme(). A number
of functions allows to manipulate buffers with names starting with the
xmlBuffer... prefix.
An Input I/O handler is a simple structure
xmlParserInputBuffer containing a context associated to the
resource (file descriptor, or pointer to a protocol handler), the read() and
close() callbacks to use and an xmlBuffer. And extra xmlBuffer and a charset
encoding handler are also present to support charset conversion when
needed.
An Output handler xmlOutputBuffer is completely similar to an
Input one except the callbacks are write() and close().
The entity loader resolves requests for new entities and create inputs for the parser. Creating an input from a filename or an URI string is done through the xmlNewInputFromFile() routine. The default entity loader do not handle the PUBLIC identifier associated with an entity (if any). So it just calls xmlNewInputFromFile() with the SYSTEM identifier (which is mandatory in XML).
If you want to hook up a catalog mechanism then you simply need to override the default entity loader, here is an example:
#include <libxml/xmlIO.h>
xmlExternalEntityLoader defaultLoader = NULL;
xmlParserInputPtr
xmlMyExternalEntityLoader(const char *URL, const char *ID,
xmlParserCtxtPtr ctxt) {
xmlParserInputPtr ret;
const char *fileID = NULL;
/* lookup for the fileID depending on ID */
ret = xmlNewInputFromFile(ctxt, fileID);
if (ret != NULL)
return(ret);
if (defaultLoader != NULL)
ret = defaultLoader(URL, ID, ctxt);
return(ret);
}
int main(..) {
...
/*
* Install our own entity loader
*/
defaultLoader = xmlGetExternalEntityLoader();
xmlSetExternalEntityLoader(xmlMyExternalEntityLoader);
...
}
This example come from a real use case, xmlDocDump() closes the FILE * passed by the application and this was a problem. The solution was to redefine a new output handler with the closing call deactivated:
xmlOutputBufferPtr
xmlOutputBufferCreateOwn(FILE *file, xmlCharEncodingHandlerPtr encoder) {
����xmlOutputBufferPtr ret;
����
����if (xmlOutputCallbackInitialized == 0)
��������xmlRegisterDefaultOutputCallbacks();
����if (file == NULL) return(NULL);
����ret = xmlAllocOutputBuffer(encoder);
����if (ret != NULL) {
��������ret->context = file;
��������ret->writecallback = xmlFileWrite;
��������ret->closecallback = NULL; /* No close callback */
����}
����return(ret);
}
FILE *f;
xmlOutputBufferPtr output;
xmlDocPtr doc;
int res;
f = ...
doc = ....
output = xmlOutputBufferCreateOwn(f, NULL);
res = xmlSaveFileTo(output, doc, NULL);
Table of Content:
What is a catalog? Basically it's a lookup mechanism used when an entity (a file or a remote resource) references another entity. The catalog lookup is inserted between the moment the reference is recognized by the software (XML parser, stylesheet processing, or even images referenced for inclusion in a rendering) and the time where loading that resource is actually started.
It is basically used for 3 things:
"-//OASIS//DTD DocBook XML V4.1.2//EN"
of the DocBook 4.1.2 XML DTD with the actual URL where it can be downloaded
http://www.oasis-open.org/docbook/xml/4.1.2/docbookx.dtd
"http://www.oasis-open.org/committes/tr.xsl"
should really be looked at
"http://www.oasis-open.org/committes/entity/stylesheets/base/tr.xsl"
Libxml, as of 2.4.3 implements 2 kind of catalogs:
In a normal environment libxml2 will by default check the presence of a catalog in /etc/xml/catalog, and assuming it has been correctly populated, the processing is completely transparent to the document user. To take a concrete example, suppose you are authoring a DocBook document, this one starts with the following DOCTYPE definition:
<?xml version='1.0'?>
<!DOCTYPE book PUBLIC "-//Norman Walsh//DTD DocBk XML V3.1.4//EN"
"http://nwalsh.com/docbook/xml/3.1.4/db3xml.dtd">
When validating the document with libxml, the catalog will be automatically consulted to lookup the public identifier "-//Norman Walsh//DTD DocBk XML V3.1.4//EN" and the system identifier "http://nwalsh.com/docbook/xml/3.1.4/db3xml.dtd", and if these entities have been installed on your system and the catalogs actually point to them, libxml will fetch them from the local disk.
Note: Really don't use this DOCTYPE example it's a really old version, but is fine as an example.
Libxml2 will check the catalog each time that it is requested to load an entity, this includes DTD, external parsed entities, stylesheets, etc ... If your system is correctly configured all the authoring phase and processing should use only local files, even if your document stays portable because it uses the canonical public and system ID, referencing the remote document.
Here is a couple of fragments from XML Catalogs used in libxml2 early
regression tests in test/catalogs :
<?xml version="1.0"?> <!DOCTYPE catalog PUBLIC "-//OASIS//DTD Entity Resolution XML Catalog V1.0//EN" "http://www.oasis-open.org/committees/entity/release/1.0/catalog.dtd"> <catalog xmlns="urn:oasis:names:tc:entity:xmlns:xml:catalog"> <public publicId="-//OASIS//DTD DocBook XML V4.1.2//EN" uri="http://www.oasis-open.org/docbook/xml/4.1.2/docbookx.dtd"/> ...
This is the beginning of a catalog for DocBook 4.1.2, XML Catalogs are
written in XML, there is a specific namespace for catalog elements
"urn:oasis:names:tc:entity:xmlns:xml:catalog". The first entry in this
catalog is a public mapping it allows to associate a Public
Identifier with an URI.
...
<rewriteSystem systemIdStartString="http://www.oasis-open.org/docbook/"
rewritePrefix="file:///usr/share/xml/docbook/"/>
...
A rewriteSystem is a very powerful instruction, it says that
any URI starting with a given prefix should be looked at another URI
constructed by replacing the prefix with an new one. In effect this acts like
a cache system for a full area of the Web. In practice it is extremely useful
with a file prefix if you have installed a copy of those resources on your
local system.
...
<delegatePublic publicIdStartString="-//OASIS//DTD XML Catalog //"
catalog="file:///usr/share/xml/docbook.xml"/>
<delegatePublic publicIdStartString="-//OASIS//ENTITIES DocBook XML"
catalog="file:///usr/share/xml/docbook.xml"/>
<delegatePublic publicIdStartString="-//OASIS//DTD DocBook XML"
catalog="file:///usr/share/xml/docbook.xml"/>
<delegateSystem systemIdStartString="http://www.oasis-open.org/docbook/"
catalog="file:///usr/share/xml/docbook.xml"/>
<delegateURI uriStartString="http://www.oasis-open.org/docbook/"
catalog="file:///usr/share/xml/docbook.xml"/>
...
Delegation is the core features which allows to build a tree of catalogs,
easier to maintain than a single catalog, based on Public Identifier, System
Identifier or URI prefixes it instructs the catalog software to look up
entries in another resource. This feature allow to build hierarchies of
catalogs, the set of entries presented should be sufficient to redirect the
resolution of all DocBook references to the specific catalog in
/usr/share/xml/docbook.xml this one in turn could delegate all
references for DocBook 4.2.1 to a specific catalog installed at the same time
as the DocBook resources on the local machine.
The user can change the default catalog behaviour by redirecting queries
to its own set of catalogs, this can be done by setting the
XML_CATALOG_FILES environment variable to a list of catalogs, an
empty one should deactivate loading the default /etc/xml/catalog
default catalog
Setting up the XML_DEBUG_CATALOG environment variable will
make libxml2 output debugging informations for each catalog operations, for
example:
orchis:~/XML -> xmllint --memory --noout test/ent2 warning: failed to load external entity "title.xml" orchis:~/XML -> export XML_DEBUG_CATALOG= orchis:~/XML -> xmllint --memory --noout test/ent2 Failed to parse catalog /etc/xml/catalog Failed to parse catalog /etc/xml/catalog warning: failed to load external entity "title.xml" Catalogs cleanup orchis:~/XML ->
The test/ent2 references an entity, running the parser from memory makes
the base URI unavailable and the the "title.xml" entity cannot be loaded.
Setting up the debug environment variable allows to detect that an attempt is
made to load the /etc/xml/catalog but since it's not present the
resolution fails.
But the most advanced way to debug XML catalog processing is to use the xmlcatalog command shipped with libxml2, it allows to load catalogs and make resolution queries to see what is going on. This is also used for the regression tests:
orchis:~/XML -> ./xmlcatalog test/catalogs/docbook.xml \
"-//OASIS//DTD DocBook XML V4.1.2//EN"
http://www.oasis-open.org/docbook/xml/4.1.2/docbookx.dtd
orchis:~/XML ->
For debugging what is going on, adding one -v flags increase the verbosity level to indicate the processing done (adding a second flag also indicate what elements are recognized at parsing):
orchis:~/XML -> ./xmlcatalog -v test/catalogs/docbook.xml \
"-//OASIS//DTD DocBook XML V4.1.2//EN"
Parsing catalog test/catalogs/docbook.xml's content
Found public match -//OASIS//DTD DocBook XML V4.1.2//EN
http://www.oasis-open.org/docbook/xml/4.1.2/docbookx.dtd
Catalogs cleanup
orchis:~/XML ->
A shell interface is also available to debug and process multiple queries (and for regression tests):
orchis:~/XML -> ./xmlcatalog -shell test/catalogs/docbook.xml \
"-//OASIS//DTD DocBook XML V4.1.2//EN"
> help
Commands available:
public PublicID: make a PUBLIC identifier lookup
system SystemID: make a SYSTEM identifier lookup
resolve PublicID SystemID: do a full resolver lookup
add 'type' 'orig' 'replace' : add an entry
del 'values' : remove values
dump: print the current catalog state
debug: increase the verbosity level
quiet: decrease the verbosity level
exit: quit the shell
> public "-//OASIS//DTD DocBook XML V4.1.2//EN"
http://www.oasis-open.org/docbook/xml/4.1.2/docbookx.dtd
> quit
orchis:~/XML ->
This should be sufficient for most debugging purpose, this was actually used heavily to debug the XML Catalog implementation itself.
Basically XML Catalogs are XML files, you can either use XML tools to manage them or use xmlcatalog for this. The basic step is to create a catalog the -create option provide this facility:
orchis:~/XML -> ./xmlcatalog --create tst.xml
<?xml version="1.0"?>
<!DOCTYPE catalog PUBLIC "-//OASIS//DTD Entity Resolution XML Catalog V1.0//EN"
"http://www.oasis-open.org/committees/entity/release/1.0/catalog.dtd">
<catalog xmlns="urn:oasis:names:tc:entity:xmlns:xml:catalog"/>
orchis:~/XML ->
By default xmlcatalog does not overwrite the original catalog and save the
result on the standard output, this can be overridden using the -noout
option. The -add command allows to add entries in the
catalog:
orchis:~/XML -> ./xmlcatalog --noout --create --add "public" \
"-//OASIS//DTD DocBook XML V4.1.2//EN" \
http://www.oasis-open.org/docbook/xml/4.1.2/docbookx.dtd tst.xml
orchis:~/XML -> cat tst.xml
<?xml version="1.0"?>
<!DOCTYPE catalog PUBLIC "-//OASIS//DTD Entity Resolution XML Catalog V1.0//EN" \
"http://www.oasis-open.org/committees/entity/release/1.0/catalog.dtd">
<catalog xmlns="urn:oasis:names:tc:entity:xmlns:xml:catalog">
<public publicId="-//OASIS//DTD DocBook XML V4.1.2//EN"
uri="http://www.oasis-open.org/docbook/xml/4.1.2/docbookx.dtd"/>
</catalog>
orchis:~/XML ->
The -add option will always take 3 parameters even if some of
the XML Catalog constructs (like nextCatalog) will have only a single
argument, just pass a third empty string, it will be ignored.
Similarly the -del option remove matching entries from the
catalog:
orchis:~/XML -> ./xmlcatalog --del \
"http://www.oasis-open.org/docbook/xml/4.1.2/docbookx.dtd" tst.xml
<?xml version="1.0"?>
<!DOCTYPE catalog PUBLIC "-//OASIS//DTD Entity Resolution XML Catalog V1.0//EN"
"http://www.oasis-open.org/committees/entity/release/1.0/catalog.dtd">
<catalog xmlns="urn:oasis:names:tc:entity:xmlns:xml:catalog"/>
orchis:~/XML ->
The catalog is now empty. Note that the matching of -del is
exact and would have worked in a similar fashion with the Public ID
string.
This is rudimentary but should be sufficient to manage a not too complex catalog tree of resources.
First, and like for every other module of libxml, there is an automatically generated API page for catalog support.
The header for the catalog interfaces should be included as:
#include <libxml/catalog.h>
The API is voluntarily kept very simple. First it is not obvious that applications really need access to it since it is the default behaviour of libxml2 (Note: it is possible to completely override libxml2 default catalog by using xmlSetExternalEntityLoader to plug an application specific resolver).
Basically libxml2 support 2 catalog lists:
oasis-xml-catalog PIs to specify its own catalog list, it is
associated to the parser context and destroyed when the parsing context
is destroyed.the document one will be used first if it exists.
xmlInitializeCatalog(), xmlLoadCatalog() and xmlLoadCatalogs() should be used at startup to initialize the catalog, if the catalog should be initialized with specific values xmlLoadCatalog() or xmlLoadCatalogs() should be called before xmlInitializeCatalog() which would otherwise do a default initialization first.
The xmlCatalogAddLocal() call is used by the parser to grow the document own catalog list if needed.
The XML Catalog spec requires the possibility to select default preferences between public and system delegation, xmlCatalogSetDefaultPrefer() allows this, xmlCatalogSetDefaults() and xmlCatalogGetDefaults() allow to control if XML Catalogs resolution should be forbidden, allowed for global catalog, for document catalog or both, the default is to allow both.
And of course xmlCatalogSetDebug() allows to generate debug messages (through the xmlGenericError() mechanism).
xmlCatalogResolve(), xmlCatalogResolveSystem(), xmlCatalogResolvePublic() and xmlCatalogResolveURI() are relatively explicit if you read the XML Catalog specification they correspond to section 7 algorithms, they should also work if you have loaded an SGML catalog with a simplified semantic.
xmlCatalogLocalResolve() and xmlCatalogLocalResolveURI() are the same but operate on the document catalog list
xmlCatalogCleanup() free-up the global catalog, xmlCatalogFreeLocal() is the per-document equivalent.
xmlCatalogAdd() and xmlCatalogRemove() are used to dynamically modify the first catalog in the global list, and xmlCatalogDump() allows to dump a catalog state, those routines are primarily designed for xmlcatalog, I'm not sure that exposing more complex interfaces (like navigation ones) would be really useful.
The xmlParseCatalogFile() is a function used to load XML Catalog files, it's similar as xmlParseFile() except it bypass all catalog lookups, it's provided because this functionality may be useful for client tools.
Since the catalog tree is built progressively, some care has been taken to try to avoid troubles in multithreaded environments. The code is now thread safe assuming that the libxml2 library has been compiled with threads support.
The XML Catalog specification is relatively recent so there isn't much literature to point at:
export XML_CATALOG_FILES=$HOME/xmlcatalog
should allow to process DocBook documentations without requiring network accesses for the DTD or stylesheets
If you have suggestions for corrections or additions, simply contact me:
This section is directly intended to help programmers getting bootstrapped using the XML tollkit from the C language. It is not intended to be extensive. I hope the automatically generated documents will provide the completeness required, but as a separate set of documents. The interfaces of the XML parser are by principle low level, Those interested in a higher level API should look at DOM.
The parser interfaces for XML are separated from the HTML parser interfaces. Let's have a look at how the XML parser can be called:
Usually, the first thing to do is to read an XML input. The parser accepts documents either from in-memory strings or from files. The functions are defined in "parser.h":
xmlDocPtr xmlParseMemory(char *buffer, int size);Parse a null-terminated string containing the document.
xmlDocPtr xmlParseFile(const char *filename);Parse an XML document contained in a (possibly compressed) file.
The parser returns a pointer to the document structure (or NULL in case of failure).
In order for the application to keep the control when the document is being fetched (which is common for GUI based programs) libxml2 provides a push interface, too, as of version 1.8.3. Here are the interface functions:
xmlParserCtxtPtr xmlCreatePushParserCtxt(xmlSAXHandlerPtr sax,
void *user_data,
const char *chunk,
int size,
const char *filename);
int xmlParseChunk (xmlParserCtxtPtr ctxt,
const char *chunk,
int size,
int terminate);
and here is a simple example showing how to use the interface:
FILE *f;
f = fopen(filename, "r");
if (f != NULL) {
int res, size = 1024;
char chars[1024];
xmlParserCtxtPtr ctxt;
res = fread(chars, 1, 4, f);
if (res > 0) {
ctxt = xmlCreatePushParserCtxt(NULL, NULL,
chars, res, filename);
while ((res = fread(chars, 1, size, f)) > 0) {
xmlParseChunk(ctxt, chars, res, 0);
}
xmlParseChunk(ctxt, chars, 0, 1);
doc = ctxt->myDoc;
xmlFreeParserCtxt(ctxt);
}
}
The HTML parser embedded into libxml2 also has a push interface; the functions are just prefixed by "html" rather than "xml".
The tree-building interface makes the parser memory-hungry, first loading
the document in memory and then building the tree itself. Reading a document
without building the tree is possible using the SAX interfaces (see SAX.h and
James
Henstridge's documentation). Note also that the push interface can be
limited to SAX: just use the two first arguments of
xmlCreatePushParserCtxt().
The other way to get an XML tree in memory is by building it. Basically there is a set of functions dedicated to building new elements. (These are also described in <libxml/tree.h>.) For example, here is a piece of code that produces the XML document used in the previous examples:
#include <libxml/tree.h>
xmlDocPtr doc;
xmlNodePtr tree, subtree;
doc = xmlNewDoc("1.0");
doc->children = xmlNewDocNode(doc, NULL, "EXAMPLE", NULL);
xmlSetProp(doc->children, "prop1", "gnome is great");
xmlSetProp(doc->children, "prop2", "& linux too");
tree = xmlNewChild(doc->children, NULL, "head", NULL);
subtree = xmlNewChild(tree, NULL, "title", "Welcome to Gnome");
tree = xmlNewChild(doc->children, NULL, "chapter", NULL);
subtree = xmlNewChild(tree, NULL, "title", "The Linux adventure");
subtree = xmlNewChild(tree, NULL, "p", "bla bla bla ...");
subtree = xmlNewChild(tree, NULL, "image", NULL);
xmlSetProp(subtree, "href", "linus.gif");
Not really rocket science ...
Basically by including "tree.h" your code has access to the internal structure of all the elements of the tree. The names should be somewhat simple like parent, children, next, prev, properties, etc... For example, still with the previous example:
doc->children->children->childrenpoints to the title element,
doc->children->children->next->children->children
points to the text node containing the chapter title "The Linux adventure".
NOTE: XML allows PIs and comments to be
present before the document root, so doc->children may point
to an element which is not the document Root Element; a function
xmlDocGetRootElement() was added for this purpose.
Functions are provided for reading and writing the document content. Here is an excerpt from the tree API:
xmlAttrPtr xmlSetProp(xmlNodePtr node, const xmlChar *name, const
xmlChar *value);This sets (or changes) an attribute carried by an ELEMENT node. The value can be NULL.
const xmlChar *xmlGetProp(xmlNodePtr node, const xmlChar
*name);This function returns a pointer to new copy of the property content. Note that the user must deallocate the result.
Two functions are provided for reading and writing the text associated with elements:
xmlNodePtr xmlStringGetNodeList(xmlDocPtr doc, const xmlChar
*value);This function takes an "external" string and converts it to one text node or possibly to a list of entity and text nodes. All non-predefined entity references like &Gnome; will be stored internally as entity nodes, hence the result of the function may not be a single node.
xmlChar *xmlNodeListGetString(xmlDocPtr doc, xmlNodePtr list, int
inLine);This function is the inverse of
xmlStringGetNodeList(). It generates a new string
containing the content of the text and entity nodes. Note the extra
argument inLine. If this argument is set to 1, the function will expand
entity references. For example, instead of returning the &Gnome;
XML encoding in the string, it will substitute it with its value (say,
"GNU Network Object Model Environment").
Basically 3 options are possible:
void xmlDocDumpMemory(xmlDocPtr cur, xmlChar**mem, int
*size);Returns a buffer into which the document has been saved.
extern void xmlDocDump(FILE *f, xmlDocPtr doc);Dumps a document to an open file descriptor.
int xmlSaveFile(const char *filename, xmlDocPtr cur);Saves the document to a file. In this case, the compression interface is triggered if it has been turned on.
The library transparently handles compression when doing file-based accesses. The level of compression on saves can be turned on either globally or individually for one file:
int xmlGetDocCompressMode (xmlDocPtr doc);Gets the document compression ratio (0-9).
void xmlSetDocCompressMode (xmlDocPtr doc, int mode);Sets the document compression ratio.
int xmlGetCompressMode(void);Gets the default compression ratio.
void xmlSetCompressMode(int mode);Sets the default compression ratio.
Entities in principle are similar to simple C macros. An entity defines an abbreviation for a given string that you can reuse many times throughout the content of your document. Entities are especially useful when a given string may occur frequently within a document, or to confine the change needed to a document to a restricted area in the internal subset of the document (at the beginning). Example:
1 <?xml version="1.0"?> 2 <!DOCTYPE EXAMPLE SYSTEM "example.dtd" [ 3 <!ENTITY xml "Extensible Markup Language"> 4 ]> 5 <EXAMPLE> 6 &xml; 7 </EXAMPLE>
Line 3 declares the xml entity. Line 6 uses the xml entity, by prefixing its name with '&' and following it by ';' without any spaces added. There are 5 predefined entities in libxml2 allowing you to escape characters with predefined meaning in some parts of the xml document content: < for the character '<', > for the character '>', ' for the character ''', " for the character '"', and & for the character '&'.
One of the problems related to entities is that you may want the parser to substitute an entity's content so that you can see the replacement text in your application. Or you may prefer to keep entity references as such in the content to be able to save the document back without losing this usually precious information (if the user went through the pain of explicitly defining entities, he may have a a rather negative attitude if you blindly substitute them as saving time). The xmlSubstituteEntitiesDefault() function allows you to check and change the behaviour, which is to not substitute entities by default.
Here is the DOM tree built by libxml2 for the previous document in the default case:
/gnome/src/gnome-xml -> ./xmllint --debug test/ent1
DOCUMENT
version=1.0
ELEMENT EXAMPLE
TEXT
content=
ENTITY_REF
INTERNAL_GENERAL_ENTITY xml
content=Extensible Markup Language
TEXT
content=
And here is the result when substituting entities:
/gnome/src/gnome-xml -> ./tester --debug --noent test/ent1
DOCUMENT
version=1.0
ELEMENT EXAMPLE
TEXT
content= Extensible Markup Language
So, entities or no entities? Basically, it depends on your use case. I suggest that you keep the non-substituting default behaviour and avoid using entities in your XML document or data if you are not willing to handle the entity references elements in the DOM tree.
Note that at save time libxml2 enforces the conversion of the predefined entities where necessary to prevent well-formedness problems, and will also transparently replace those with chars (i.e. it will not generate entity reference elements in the DOM tree or call the reference() SAX callback when finding them in the input).
WARNING: handling entities on top of the libxml2 SAX interface is difficult!!! If you plan to use non-predefined entities in your documents, then the learning curve to handle then using the SAX API may be long. If you plan to use complex documents, I strongly suggest you consider using the DOM interface instead and let libxml deal with the complexity rather than trying to do it yourself.
The libxml2 library implements XML namespaces support by recognizing namespace constructs in the input, and does namespace lookup automatically when building the DOM tree. A namespace declaration is associated with an in-memory structure and all elements or attributes within that namespace point to it. Hence testing the namespace is a simple and fast equality operation at the user level.
I suggest that people using libxml2 use a namespace, and declare it in the root element of their document as the default namespace. Then they don't need to use the prefix in the content but we will have a basis for future semantic refinement and merging of data from different sources. This doesn't increase the size of the XML output significantly, but significantly increases its value in the long-term. Example:
<mydoc xmlns="http://mydoc.example.org/schemas/"> <elem1>...</elem1> <elem2>...</elem2> </mydoc>
The namespace value has to be an absolute URL, but the URL doesn't have to
point to any existing resource on the Web. It will bind all the element and
attributes with that URL. I suggest to use an URL within a domain you
control, and that the URL should contain some kind of version information if
possible. For example, "http://www.gnome.org/gnumeric/1.0/" is a
good namespace scheme.
Then when you load a file, make sure that a namespace carrying the
version-independent prefix is installed on the root element of your document,
and if the version information don't match something you know, warn the user
and be liberal in what you accept as the input. Also do *not* try to base
namespace checking on the prefix value. <foo:text> may be exactly the
same as <bar:text> in another document. What really matters is the URI
associated with the element or the attribute, not the prefix string (which is
just a shortcut for the full URI). In libxml, element and attributes have an
ns field pointing to an xmlNs structure detailing the namespace
prefix and its URI.
@@Interfaces@@
xmlNodePtr node;
if(!strncmp(node->name,"mytag",5)
&& node->ns
&& !strcmp(node->ns->href,"http://www.mysite.com/myns/1.0")) {
...
}
Usually people object to using namespaces together with validity checking.
I will try to make sure that using namespaces won't break validity checking,
so even if you plan to use or currently are using validation I strongly
suggest adding namespaces to your document. A default namespace scheme
xmlns="http://...." should not break validity even on less
flexible parsers. Using namespaces to mix and differentiate content coming
from multiple DTDs will certainly break current validation schemes. To check
such documents one needs to use schema-validation, which is supported in
libxml2 as well. See relagx-ng and w3c-schema.
Incompatible changes:
Version 2 of libxml2 is the first version introducing serious backward incompatible changes. The main goals were:
So client code of libxml designed to run with version 1.x may have to be changed to compile against version 2.x of libxml. Here is a list of changes that I have collected, they may not be sufficient, so in case you find other change which are required, drop me a mail:
Note also that with the new default the output functions don't add any extra indentation when saving a tree in order to be able to round trip (read and save) without inflating the document with extra formatting chars.
xml2-config --cflags
output to generate you compile commands this will probably work out of the box
Two new version of libxml (1.8.11) and libxml2 (2.3.4) have been released to allow smooth upgrade of existing libxml v1code while retaining compatibility. They offers the following:
So the roadmap to upgrade your existing libxml applications is the following:
Following those steps should work. It worked for some of my own code.
Let me put some emphasis on the fact that there is far more changes from libxml 1.x to 2.x than the ones you may have to patch for. The overall code has been considerably cleaned up and the conformance to the XML specification has been drastically improved too. Don't take those changes as an excuse to not upgrade, it may cost a lot on the long term ...
Starting with 2.4.7, libxml2 makes provisions to ensure that concurrent threads can safely work in parallel parsing different documents. There is however a couple of things to do to ensure it:
Note that the thread safety cannot be ensured for multiple threads sharing the same document, the locking must be done at the application level, libxml exports a basic mutex and reentrant mutexes API in <libxml/threads.h>. The parts of the library checked for thread safety are:
XPath is supposed to be thread safe now, but this wasn't tested seriously.
DOM stands for the Document Object Model; this is an API for accessing XML or HTML structured documents. Native support for DOM in Gnome is on the way (module gnome-dom), and will be based on gnome-xml. This will be a far cleaner interface to manipulate XML files within Gnome since it won't expose the internal structure.
The current DOM implementation on top of libxml2 is the gdome2 Gnome module, this is a full DOM interface, thanks to Paolo Casarini, check the Gdome2 homepage for more informations.
Here is a real size example, where the actual content of the application data is not kept in the DOM tree but uses internal structures. It is based on a proposal to keep a database of jobs related to Gnome, with an XML based storage structure. Here is an XML encoded jobs base:
<?xml version="1.0"?>
<gjob:Helping xmlns:gjob="http://www.gnome.org/some-location">
<gjob:Jobs>
<gjob:Job>
<gjob:Project ID="3"/>
<gjob:Application>GBackup</gjob:Application>
<gjob:Category>Development</gjob:Category>
<gjob:Update>
<gjob:Status>Open</gjob:Status>
<gjob:Modified>Mon, 07 Jun 1999 20:27:45 -0400 MET DST</gjob:Modified>
<gjob:Salary>USD 0.00</gjob:Salary>
</gjob:Update>
<gjob:Developers>
<gjob:Developer>
</gjob:Developer>
</gjob:Developers>
<gjob:Contact>
<gjob:Person>Nathan Clemons</gjob:Person>
<gjob:Email>nathan@windsofstorm.net</gjob:Email>
<gjob:Company>
</gjob:Company>
<gjob:Organisation>
</gjob:Organisation>
<gjob:Webpage>
</gjob:Webpage>
<gjob:Snailmail>
</gjob:Snailmail>
<gjob:Phone>
</gjob:Phone>
</gjob:Contact>
<gjob:Requirements>
The program should be released as free software, under the GPL.
</gjob:Requirements>
<gjob:Skills>
</gjob:Skills>
<gjob:Details>
A GNOME based system that will allow a superuser to configure
compressed and uncompressed files and/or file systems to be backed
up with a supported media in the system. This should be able to
perform via find commands generating a list of files that are passed
to tar, dd, cpio, cp, gzip, etc., to be directed to the tape machine
or via operations performed on the filesystem itself. Email
notification and GUI status display very important.
</gjob:Details>
</gjob:Job>
</gjob:Jobs>
</gjob:Helping>
While loading the XML file into an internal DOM tree is a matter of calling only a couple of functions, browsing the tree to gather the data and generate the internal structures is harder, and more error prone.
The suggested principle is to be tolerant with respect to the input structure. For example, the ordering of the attributes is not significant, the XML specification is clear about it. It's also usually a good idea not to depend on the order of the children of a given node, unless it really makes things harder. Here is some code to parse the information for a person:
/*
* A person record
*/
typedef struct person {
char *name;
char *email;
char *company;
char *organisation;
char *smail;
char *webPage;
char *phone;
} person, *personPtr;
/*
* And the code needed to parse it
*/
personPtr parsePerson(xmlDocPtr doc, xmlNsPtr ns, xmlNodePtr cur) {
personPtr ret = NULL;
DEBUG("parsePerson\n");
/*
* allocate the struct
*/
ret = (personPtr) malloc(sizeof(person));
if (ret == NULL) {
fprintf(stderr,"out of memory\n");
return(NULL);
}
memset(ret, 0, sizeof(person));
/* We don't care what the top level element name is */
cur = cur->xmlChildrenNode;
while (cur != NULL) {
if ((!strcmp(cur->name, "Person")) && (cur->ns == ns))
ret->name = xmlNodeListGetString(doc, cur->xmlChildrenNode, 1);
if ((!strcmp(cur->name, "Email")) && (cur->ns == ns))
ret->email = xmlNodeListGetString(doc, cur->xmlChildrenNode, 1);
cur = cur->next;
}
return(ret);
}
Here are a couple of things to notice:
Here is another piece of code used to parse another level of the structure:
#include <libxml/tree.h>
/*
* a Description for a Job
*/
typedef struct job {
char *projectID;
char *application;
char *category;
personPtr contact;
int nbDevelopers;
personPtr developers[100]; /* using dynamic alloc is left as an exercise */
} job, *jobPtr;
/*
* And the code needed to parse it
*/
jobPtr parseJob(xmlDocPtr doc, xmlNsPtr ns, xmlNodePtr cur) {
jobPtr ret = NULL;
DEBUG("parseJob\n");
/*
* allocate the struct
*/
ret = (jobPtr) malloc(sizeof(job));
if (ret == NULL) {
fprintf(stderr,"out of memory\n");
return(NULL);
}
memset(ret, 0, sizeof(job));
/* We don't care what the top level element name is */
cur = cur->xmlChildrenNode;
while (cur != NULL) {
if ((!strcmp(cur->name, "Project")) && (cur->ns == ns)) {
ret->projectID = xmlGetProp(cur, "ID");
if (ret->projectID == NULL) {
fprintf(stderr, "Project has no ID\n");
}
}
if ((!strcmp(cur->name, "Application")) && (cur->ns == ns))
ret->application = xmlNodeListGetString(doc, cur->xmlChildrenNode, 1);
if ((!strcmp(cur->name, "Category")) && (cur->ns == ns))
ret->category = xmlNodeListGetString(doc, cur->xmlChildrenNode, 1);
if ((!strcmp(cur->name, "Contact")) && (cur->ns == ns))
ret->contact = parsePerson(doc, ns, cur);
cur = cur->next;
}
return(ret);
}
Once you are used to it, writing this kind of code is quite simple, but boring. Ultimately, it could be possible to write stubbers taking either C data structure definitions, a set of XML examples or an XML DTD and produce the code needed to import and export the content between C data and XML storage. This is left as an exercise to the reader :-)
Feel free to use the code for the full C parsing example as a template, it is also available with Makefile in the Gnome CVS base under gnome-xml/example